Writing
A self-tuning kubernetes homelab
How I built a self-tuning Kubernetes homelab workflow that opens safe resource tuning PRs automatically.
Every now and then, I wake up to a pull request. It looks something like this:
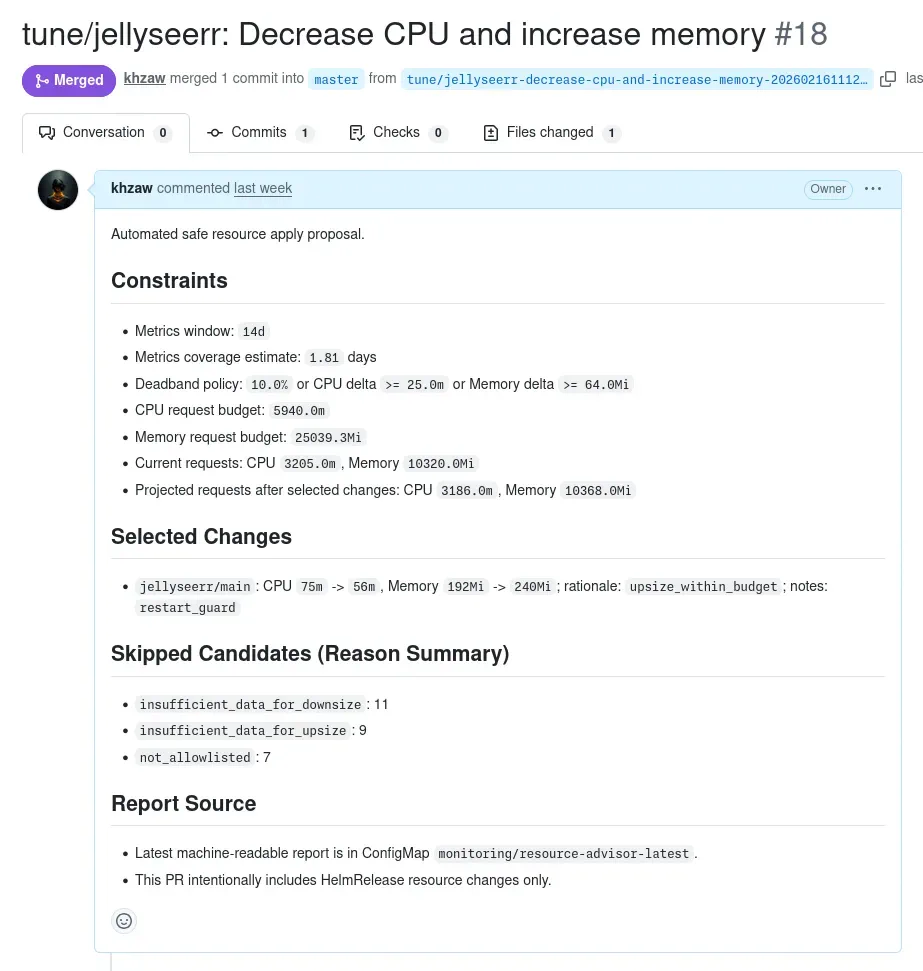
The diff is a handful of Kubernetes resource request and limit changes across a couple of HelmRelease manifests. The PR description explains why each change was made: which containers need more memory, which ones are overprovisioned, how the proposed state fits on each node. I review it, click merge, and Flux rolls it out. That’s it.
Nobody wrote that PR. A CronJob in the cluster did.
The problem
I run about 25 services and counting on a two-node Kubernetes cluster at home. One is a Lenovo m720q mini PC. The other is a Raspberry Pi 4. That’s all the compute I have in the cluster.
When you set resource requests and limits for workloads in Kubernetes, you’re usually guessing. You look at what the app does, pick some round numbers, and move on. Over time the cluster accumulates a mix of overprovisioned pods hoarding capacity and underprovisioned pods getting throttled or OOM-killed. In a cloud environment you can throw more compute resources at it. In a homelab with two nodes and a fixed memory ceiling, you can’t.
I wanted something that would watch actual usage, figure out what each container really needs, and propose changes as pull requests with rationale, so I can review and merge when I’m ready. The whole cluster is managed with Flux CD GitOps, so a merged PR is all it takes to roll out a change.
The solution
The result is a small Python script called resource-advisor. It runs as a pair of Kubernetes CronJobs:
- A daily report job queries Prometheus for real usage data and publishes recommendations to a ConfigMap.
- A weekly apply job takes those recommendations, simulates whether the changes fit on each node, patches the HelmRelease files, and opens a PR on GitHub.
No VPA, no external SaaS, no custom operator. Just a Python script, a ConfigMap, and some guardrails.
The script is mounted into a stock python:3.12-alpine container from a ConfigMap generated by Kustomize. No container image to build or push.
How it works
Collecting metrics
The core input is p95 CPU and memory usage over a 14-day rolling window, pulled from Prometheus:
cpu_query = (
f'quantile_over_time(0.95, rate(container_cpu_usage_seconds_total'
f'{{namespace="{namespace}",pod=~"{pod_regex}",'
f'container="{container_name}",image!=""}}[5m])'
f'[{metrics_window}:{metrics_resolution}])'
)
mem_query = (
f'quantile_over_time(0.95, container_memory_working_set_bytes'
f'{{namespace="{namespace}",pod=~"{pod_regex}",'
f'container="{container_name}",image!=""}})'
f'[{metrics_window}:{metrics_resolution}])'
)
Why p95 and not average? Because averages hide spikes. If Sonarr (a TV show download manager) is idle 23 hours a day but burns 400m CPU during an indexer sync, the average says 20m. The p95 says 400m. The request needs to cover the spike or the pod gets CPU-throttled during the one time it actually matters.
Restart counts are also tracked over the same window. This feeds the restart guard, which I’ll get to shortly.
Computing recommendations
Once we have the p95 values, the recommendation logic is straightforward. Start from observed usage, add a safety buffer, and clamp the step size so changes don’t shock the system:
# Target = p95 usage + 30% buffer for requests
target_req_cpu = max(min_cpu_m, cpu_p95_m * 1.30)
target_req_mem = max(min_mem_mi, mem_p95_mi * 1.30)
# Limits get a wider buffer (60%) and a floor relative to requests
target_lim_cpu = max(target_req_cpu * 2.0, cpu_p95_m * 1.60)
target_lim_mem = max(target_req_mem * 1.5, mem_p95_mi * 1.60)
# Cap the per-run adjustment to 25% of current value
rec_req_cpu = recommend(cur_req_cpu, target_req_cpu, max_step_percent=25)
The recommend function clamps the target within a step bound around the current value:
def recommend(current, target, max_step_percent):
if current <= 0:
return target
step = max_step_percent / 100.0
low = current * (1.0 - step)
high = current * (1.0 + step)
return clamp(target, low, high)
So if a container currently has 100m CPU and the target is 200m, the first run recommends 125m. Next week, ~156m. It converges over a few cycles instead of making a single large jump. This matters because metrics lag reality. A container that was just resized needs time to generate new usage patterns at its new resource level.
Small changes are noise, so there’s a deadband filter. If the recommendation differs from the current value by less than 10% or less than 25m CPU / 64Mi memory, it gets dropped. Without this, the system would churn out PRs adjusting a service from, say, 47m to 52m every week.
Guardrails
Automated resource changes need safety mechanisms.
The most important one is the restart guard. If a container had restarts during the metrics window, memory downsizing is blocked:
if restart_lookback > 0:
if rec_req_mem < cur_req_mem:
rec_req_mem = cur_req_mem
if rec_lim_mem < cur_lim_mem:
rec_lim_mem = cur_lim_mem
Restarts often indicate OOM kills. Reducing memory for a container that’s already getting killed is the opposite of helpful. CPU can still be adjusted since CPU throttling doesn’t cause restarts.
Some workloads have highly variable resource usage, like transcoding in Jellyfin or ML inference in Immich (a self-hosted photo management service). These are excluded from any downsizing but can still be upsized.
Prometheus might not have enough data for a newly deployed app either. Both upsizes and downsizes require at least 14 days of metrics coverage before the system will propose changes. The only exception is restart-guarded upsizes, because a container that’s restarting needs more memory now, not in two weeks.
Finally, each weekly PR contains at most 5 changes to bound the blast radius.
Node-fit simulation
This is where it gets interesting. A recommendation might look correct in isolation, but the cluster can’t actually schedule it. My two nodes have very different capacities. The Lenovo mini PC has 32GB RAM. The Pi has 8GB. Most workloads run on the Lenovo mini PC.
Before selecting which changes to include in a PR, the system queries the Kubernetes API for live node capacity and current pod placement. It enforces a capacity budget: total requests must not exceed 60% of allocatable CPU and 65% of allocatable memory, both cluster-wide and per-node.
def check_fit(projected_by_node):
total_cpu, total_mem = totals(projected_by_node)
ok = True
# Cluster-wide budget
if total_cpu > cpu_budget_m or total_mem > mem_budget_mi:
ok = False
# Per-node budget
for name in node_alloc:
cpu = projected_by_node[name]["cpu_m"]
mem = projected_by_node[name]["mem_mi"]
if cpu > node_cpu_budget[name] or mem > node_mem_budget[name]:
ok = False
return ok
A change that fits globally but overloads node gets rejected. The budget ceiling is intentionally conservative. Kubernetes needs headroom for the kubelet, system daemons, and scheduling flexibility. Running at 95% request utilization on a homelab means the next pod you deploy has nowhere to go.
When an upsize doesn’t fit, the system tries to find downsizes that free enough capacity. It scores candidate downsizes by how much they reduce the specific overage, with a bonus for targeting the same node where the upsize needs to run. If Jellyfin needs more memory but the node budget is full, the planner might select a Radarr (movie library manager) downsize and a Prowlarr (indexer manager) downsize to make room. The PR description explains exactly why each change was selected and which tradeoffs were made.
Patching and PR creation
The cluster is managed entirely through GitOps. Every app is a Flux HelmRelease. Resource requests and limits live inside the values: section, nested under controllers.main.containers.<name>.resources. The script patches these files via the GitHub API.
The weekly job creates a branch, commits the patched files, and opens a PR. The PR description includes policy constraints, a snapshot showing allocatable vs. projected requests per node, the selected changes with rationale, skipped candidates and tradeoff suggestions when upsizes were blocked by capacity.
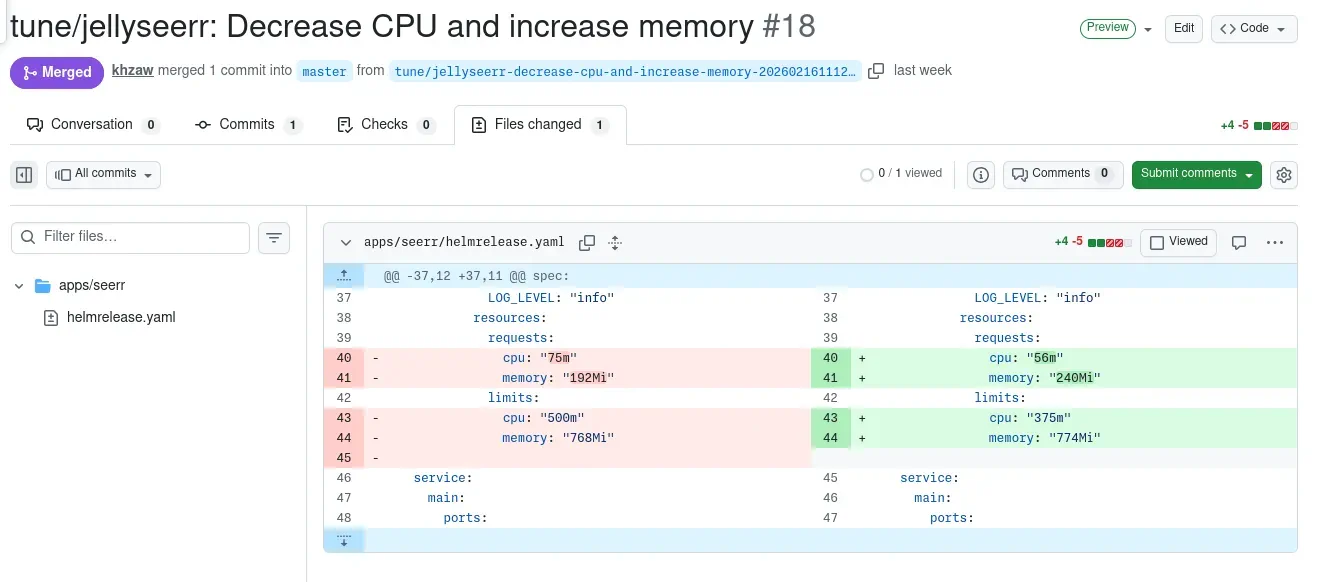
I review, merge, and Flux reconciles. Pods roll out with the new resource settings. The next daily report captures the new baseline and the cycle continues.
Observability
A small exporter deployment continuously polls the report ConfigMap and serves a human-readable summary along with Prometheus metrics like recommendation counts by action (upsize/downsize) and current cluster request utilization as a percentage of allocatable capacity.
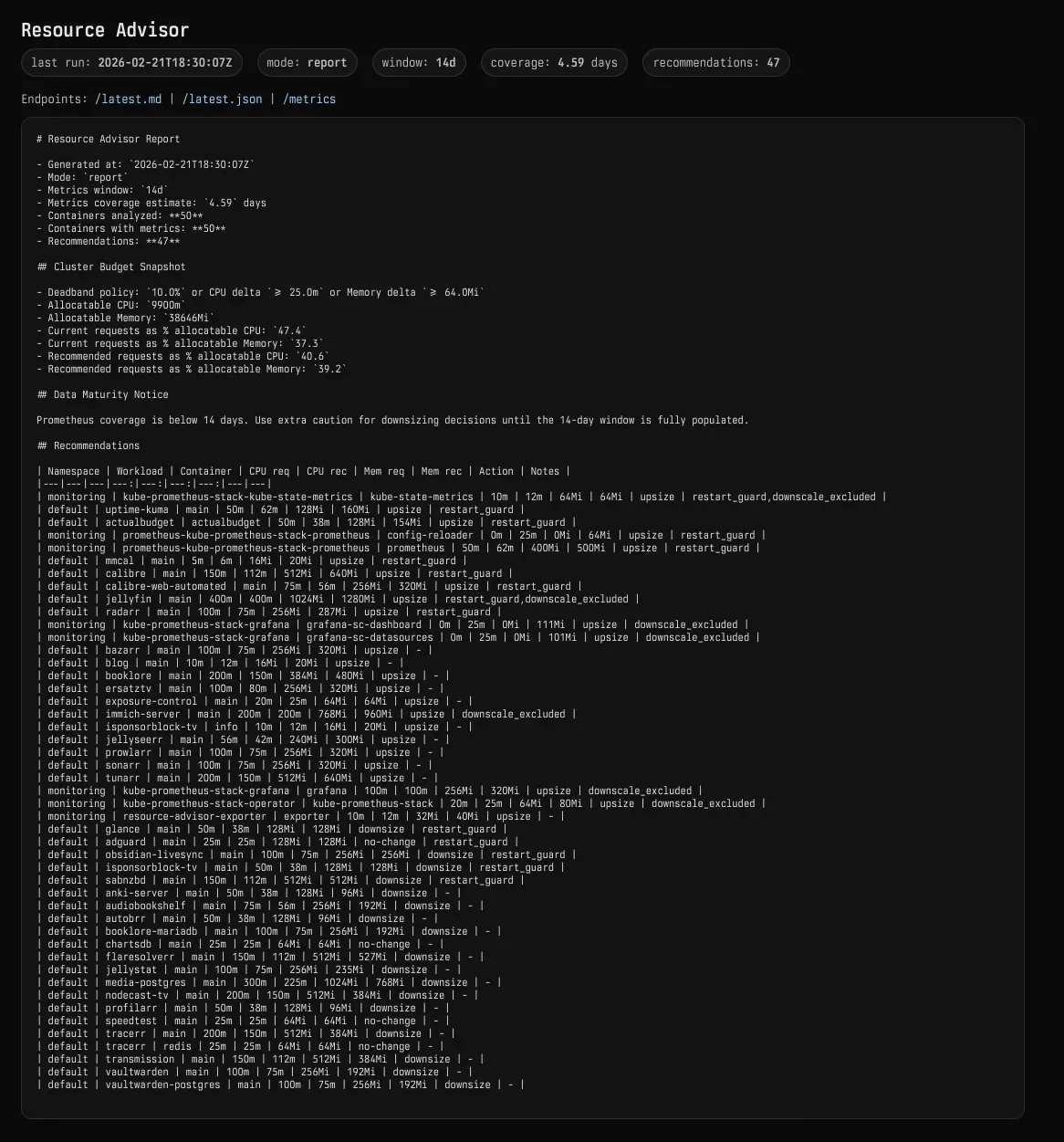
These metrics feed a Grafana dashboard that shows cluster budget utilization over time and recommendation trends. If the budget utilization line is trending up, I know I’m slowly running out of room.

Why not VPA?
Kubernetes has a Vertical Pod Autoscaler. VPA in Auto mode restarts pods to apply changes, which is disruptive for stateful apps like Jellyfin mid-stream. It operates per-deployment with no concept of cluster-wide capacity budgets or node-fit constraints, so it can happily recommend values that won’t schedule. It also doesn’t integrate with GitOps since it mutates live resources directly, causing Git state and cluster state to diverge. And its recommendation algorithm is opaque. I wanted to see exactly why a change was proposed and have control over the policy.
The resource-advisor approach trades real-time reactivity for predictability and auditability. Changes are batched weekly, reviewed as code, and applied through the same GitOps pipeline as everything else.
Results
After running this for several weeks, the cluster settled into a steady state. Most apps turned out to be overprovisioned, a few were underprovisioned and the restart guard caught those early. Changes converge gradually over 2-4 weeks thanks to the step cap, which gives enough time to observe the effect of each increment before the next one lands.
The total functionality is achieved by one Python file, some RBAC manifests, and two CronJob definitions. No framework, no operator, no CRDs. It runs in a stock Alpine container with zero dependencies beyond the standard library.
Sometimes the best homelab infrastructure is the one that monitors its usage, tunes itself, and stays quiet.